Credit Risk Classification
The Business Problem
Financial institutions need to accurately predict the likelihood of loan default to minimize bad debt. However, default datasets are inherently imbalanced (most people pay back their loans), which makes standard models biased towards the majority class.
Goal: Build a machine learning model that accurately identifies high-risk borrowers without rejecting too many creditworthy applicants.
Data Exploration & Preprocessing
The dataset contained 32,581 records. Key preprocessing steps included:
- Outlier Removal: Removed erroneous records (e.g., age > 100).
- Imputation: Filled missing interest rate values using the median.
- Encoding: Applied One-Hot Encoding to categorical features like 'Home Ownership' and 'Loan Intent'.
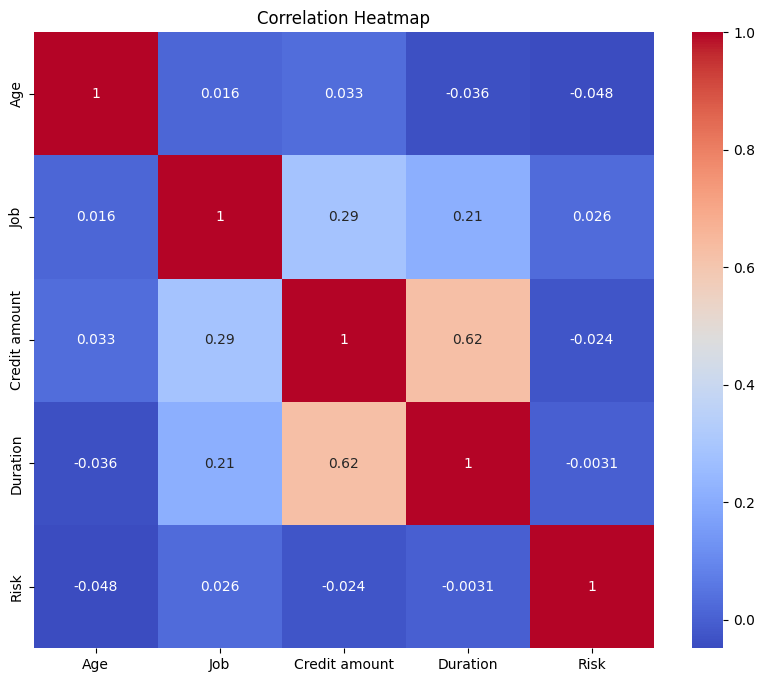
Figure 1: Correlation Matrix identifying relationships between Loan Status and Interest Rate.
Handling Imbalance with SMOTE
Since defaults were a minority class, I used SMOTE (Synthetic Minority Over-sampling Technique) to balance the training data. This ensures the model learns to detect defaults rather than just guessing "Non-Default" every time.
# Handling Class Imbalance
from imblearn.over_sampling import SMOTE
smote = SMOTE(random_state=42)
X_resampled, y_resampled = smote.fit_resample(X, y)
print(f"Original Class Distribution: {Counter(y)}")
print(f"Resampled Class Distribution: {Counter(y_resampled)}")
Model Comparison
I tested three algorithms: Decision Tree, Random Forest, and XGBoost. Random Forest proved to be the most robust.
# Random Forest Implementation
rf_model = RandomForestClassifier(n_estimators=200, random_state=42)
rf_model.fit(X_train, y_train)
# Accuracy on Test Set: 93.4%
Results & Impact
The model identified that Loan Interest Rate and Loan-to-Income Ratio are the strongest predictors of default. By deploying this model, the bank can automate risk assessment for 80% of applicants while flagging high-risk cases for manual review.
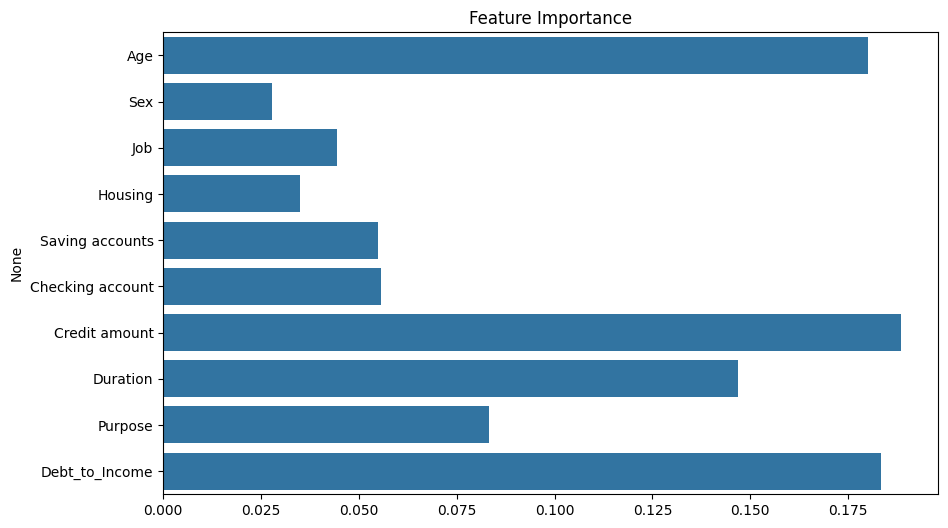
Figure 2: Confusion Matrix showing high precision in detecting defaults.
Balancing Growth vs. Risk?
I design predictive scoring models that automate decision-making. If you need to identify high-risk exposures without slowing down business approvals, I can help build the solution.
Discuss Risk Modeling